


mysql 不支持 FULL JOIN,但可以通过其他方式模拟 FULL JOIN 的效果。
一种实现 FULL JOIN 的方法是使用 UNION 操作符和 LEFT JOIN、RIGHT JOIN 结合起来,具体步骤如下:
使用 LEFT JOIN 将左表和右表连接起来,并将右表中匹配不到的行填充为 NULL。
使用 RIGHT JOIN 将右表和左表连接起来,并将左表中匹配不到的行填充为 NULL。
使用 UNION 将两个结果集合并起来,并去掉重复的行。
这时候,只需要给表join查询的字段,及表结构,进行索引优化,即可解决这个慢的问题。
一,首先利用explain 关键字对查询的SQL进行分析。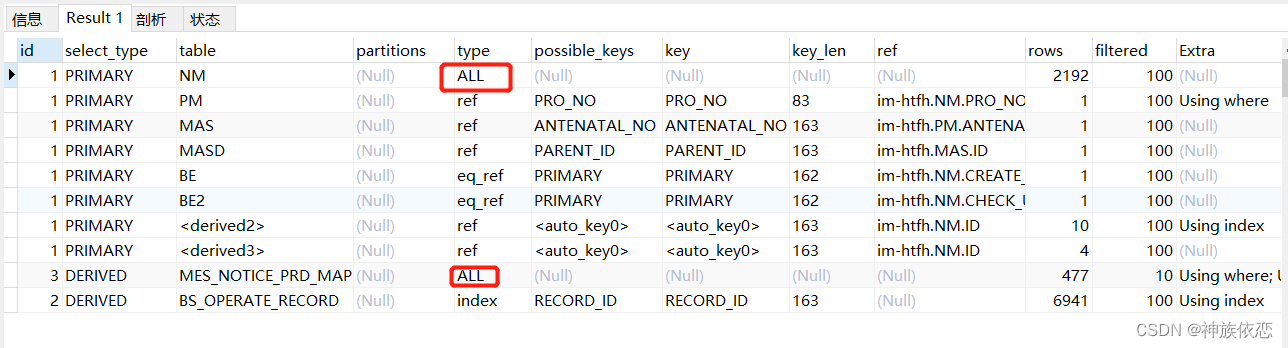
type=ALL,全表扫描,MySQL遍历全表来找到匹配行
type=index,索引全扫描,MySQL遍历整个索引来查询匹配行,并不会扫描表
type=range,索引范围扫描,常用于<、<=、>、>=、between等操作
type=ref,使用非唯一索引或唯一索引的前缀扫描,返回匹配某个单独值的记录行
type=eq_ref,类似ref,区别在于使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配
type=const/system,单表中最多有一条匹配行,查询起来非常迅速,所以这个匹配行的其他列的值可以被优化器在当前查询中当作常量来处理
type=NULL,MySQL不用访问表或者索引,直接就能够得到结果
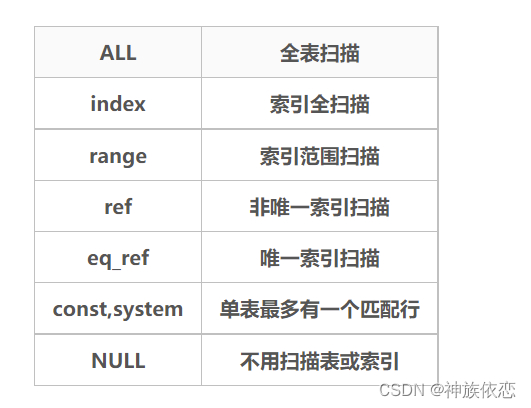
all < index < range < index_subquery < unique_subquery < index_merge < ref_or_null < ref < eq_ref < const < system
*** 重点来了,为表添加索引,如果发现分析出来的表type 为all ,我们首先想到这个表没加索引,我们给他加上 ***
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引
mysql引擎放弃使用索引而进行全表扫描的几种情况:
应尽量避免在 where 子句中对字段进行 null 值判断,可以设置默认值0
应尽量避免在 where 子句中使用!=或<>操作符
应尽量避免在 where 子句中使用or 来连接条件,in 和 not in 也要慎用
模糊查询select id from t where name like ‘%李%’也会全表扫描,若要提高效率,可以考虑全文检索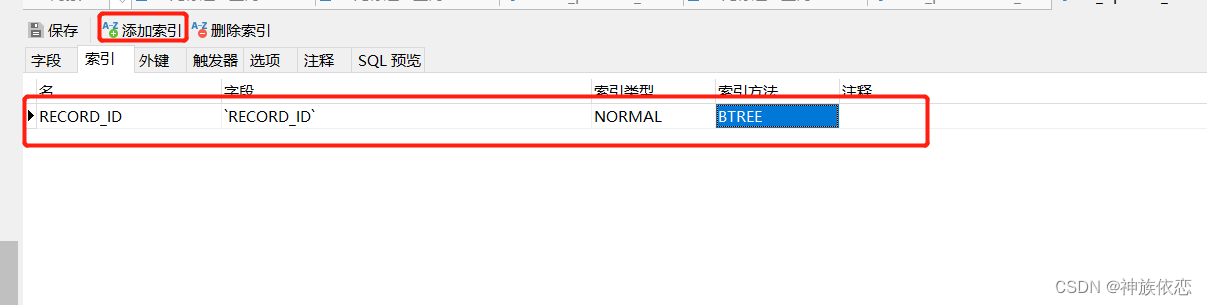
------------------添加完后--大功告成----------------------
1MySQL目前主要有以下几种索引类型:
1.普通索引2.唯一索引3.主键索引4.组合索引5.全文索引
mysql Hash索引和BTree索引区别
一、BTree
BTree索引是最常用的mysql数据库索引算法,因为它不仅可以被用在=,>,>=,<,<=和between这些比较操作符上,而且还可以用于like操作符,只要它的查询条件是一个不以通配符开头的常量,例如:
select from user where name like ‘jack%’;
select from user where name like ‘jac%k%’;
如果一通配符开头,或者没有使用常量,则不会使用索引,例如:
select from user where name like ‘%jack’;
select from user where name like simply_name;
一、Hash
hash索引查找数据基本上能一次定位数据,当然有大量碰撞的话性能也会下降。而btree索引就得在节点上挨着查找了,很明显在数据精确查找方面hash索引的效率是要高于btree的;
那么不精确查找呢,也很明显,因为hash算法是基于等值计算的,所以对于“like”等范围查找hash索引无效,不支持;
对于btree支持的联合索引的最优前缀,hash也是无法支持的,联合索引中的字段要么全用要么全不用。提起最优前缀居然都泛起迷糊了,看来有时候放空得太厉害;
hash不支持索引排序,索引值和计算出来的hash值大小并不一定一致。
MySQL是只支持一种JOIN算法Nested-Loop Join(嵌套循环链接) —
没有索引时会走,Block Nested-Loop Join比Simple Nested-Loop Join多了一个中间join buffer缓冲处理的过程
没有索引时:
关于 left join的优化
根据上面咱们的对比,基本可以总结出来一些简单的优化方案
1、left join选择小表作为驱动表(这部分基本是大家的共识)
2、如果左表比较大,并且业务要求驱动表必须是左表,那么我们可以通过where条件语句,使得左表被过滤的小一些,主要原理和第一条类似
3、关联字段给索引,因为在mysql的嵌套循环算法中,是通过关联字段进行关联,并查询的,所以给关联字段索引很必要
4、如果sql里面有排序,请给排序字段加上索引,不然会造成排序使用全表扫描
5、如果where条件中含有右表的非空条件(除开is null),则left join语句等同于join语句,可直接改写成join语句
6、根据文档,MySQL能更高效地在声明具有相同类型和尺寸的列上使用索引。所以把表与表之间的关联字段给上encoding和collation(决定字符比较的规则)全部改成统一的类型
7、右表的条件列一定要加上索引(主键、唯一索引、前缀索引等),最好能够使type达到range及以上(ref,eq_ref,const,system)
可参考
mysql 多个left join 怎么优化? - OSCHINA - 中文开源技术交流社区
从一个MySQL left join优化的例子加深对查询计划的理解 - 移动互联网的浪潮来了,我能捞点虾兵蟹将吗 - ITeye博客
join 是进行两个或多个数据表进行关联查询的过程中,经常使用的一种查询手段。提到join,你一定会想到"笛卡尔积",当数据量很大的时候,"笛卡尔积"运算量会成倍的增加,在我们的印象中,join是一种运算效率不高的查询语句。除了定性的判断join慢之外,你能定量的判断join的执行效率吗?经过下面对join执行效率定量分析后,可能你会改变对join的认识,不在想当然的认为join就一定很慢了。
驱动表与被驱动表
进行join操作的两个表,分别称为驱动表和被驱动表,到底哪个是驱动表,哪个是被驱动表是不确定的,这个是mysql优化器来决定,和sql语句中两个表的位置没有关系。如果我们想要强制指定两个表的对应关系,可以将sql中的join替换成 straight_join,替换后,在straight_join前的表称为驱动表,在straight_join后的表,称为被驱动表。
驱动表和被驱动表有什么差异
在join语句执行的过程中,驱动表和被驱动表所执行的操作是不同的。同是驱动表或被驱动表,在不同的join类型中,所执行操作也是不同的。
下面我们分析一下,不同join类型下,驱动表和被驱动表所做的操作的具体内容。
为了方便下面问题的讨论,我们建立如下的表结构:
create table 'table1' ('id' int(11) NOT NULL,
'a' int(11) DEFAULT NULL,
'b' int(11) DEFAULT NULL,
PRIMARY KEY ('id'),
KEY 'a' ('a')
) engine = Innodb;
insert into table1 values(1,1,1)
insert into table1 values(2,2,2)
...
insert into table1 values(1000,1000,1000) // 也可以使用存储过程来实现大批量数据的插入
create table table2 like table1;
insert into t2 (select * from t2 where id <= 100)
建立表结构完全相同的两个表table1和table2,共有三个字段:id为主键字段,索引字段a和普通字段b。向table1中插入了1000行自增的数据,将table1中的前100行数据插入到table2中。
基于索引的join
如果在join过程中,使用到了索引,这种join又被称为 Index Nested-Loop Join(NLJ)。
如下面这个语句:
select * from table2 straight_join table1 on table2.a = table1.a;为了便于明确驱动表和被驱动表,我们使用 straight_join 代替 join,这样就可以明确 table2 为驱动表,table1为被驱动表。
因为在被驱动表 table1上有索引a字段,在join的时候,会使用到这个索引,具体可以通过查看上面sql的执行计划:
explain select * from table2 straight_join table1 on table2.a = table1.a;执行计划图:

该条语句的执行过程如下:
1.从table2中,读入一行R。
2.从该数据行R中取出字段a,到table1中去查找满足a=$R.a的数据行,因为在table1表中,字段a上有索引,所以这个查询效率很高。
3.将从2中查询返回的结果和R,构成结果集中一行。
4.重复步骤1到3,直到遍历完table2中的所有数据行。
这个过程遍历 table2中的所有数据行,取出每一行中的a值,然后去table1中查找满足条件的数据行,将table1中满足条件的数据和table2中遍历到的数据,组合成结果集中的数据。
在整个过程中:
驱动表table2所做的操作:被逐行遍历,也就是进行全表扫描,该过程要扫描100行数据。
被驱动表table1所做的操作:基于索引字段进行数据查询,因为table1中,没有a值相同的两行数据,所以每次搜索过程只会扫描一行数据。因为table2中有100行数,所以在table1中要执行100次搜索过程,也就是在table1中,也要扫描100行数据。
所以这个join语句整个执行下来 要扫描200行数。
如果让 table1作为驱动表,table2作为被驱动表的话,执行语句如下:
select * from table1 straight_join table2 on table2.a = table1.a;和前者有和区别呢?
根据上面的分析,驱动表需要进行全表扫描,被驱动表基于索引字段进行数据搜索。
table1作为驱动表时,sql语句执行计划如下图:

当 table1作为驱动表,table2作为被驱动表时:
驱动表table1需要被扫描 1000行。被驱动表table2需要进行 1000次搜索,但是最终只能成功搜索到100行数据。总的所有数据行数1100行。
这样对比下来,table2作为驱动表,table1作为被驱动表执行的效率,要比table1作为驱动表,table2作为被驱动表的执行效率要高一些。
join查询中如何选择驱动表
除了分析扫描行数,我们可以对NLJ执行过程中,总的时间复杂度计算一下,看一下哪个因素对join查询效率影响比较大,进而来对我们选择驱动表提供参考。
我们假设驱动表中的数据行数是N,被驱动表中的数据行数为M,因为在被驱动表中查询一行数据,要先搜索普通索引a,然后再回表到主键索引,才能获取完整的一行数据。
表中数据行数为M,通过主键索引树和普通索引树查找一行数据的时间复杂度都是log2M,所以查找一行数据的时间复杂度为2*log2M。驱动表中有N行数,因此驱动表要扫描N行,驱动表中的每行数据都要到被驱动表中进行一次搜索。所以当驱动表数据行数为N,被驱动表数据行数为M的情况下,一次基于索引的join查询的近似时间复杂度为 O = N + N*2*log2M。
整个join语句的时间复杂度,与驱动表中行数的关系为: O = (1+2*log2M)*N ,是线性关系。和被驱动表中行数的关系为:O = N*2*log2M +N 是对数函数关系。
基于数学知识,我们知道 "驱动表中行数"对整个sql执行时间复杂度的影响 要比"被驱动表中行数" 影响要大。因此在 基于索引的join(NLJ)中,我们应该尽量使用 数据量小的表作为驱动表。这样可以减少扫描的行数,以及整体的时间复杂度。
不使用join,执行效率是否会更高
如果不使用join的情况下,要想实现下图类似功能,
select * from table2 join table1 on table2.a = table1.a;我们需要把 table2中的数据全部取出来,
select * from table2; // 扫描100行数据共100行数据,然后循环遍历这100行数据,取出每行数据中的a值$R.a,去执行
select * from table1 where a = $R.a // 扫描1行数据把该条语句返回的结果 和R拼接在一起,构成结果集中的一行数据。
这种不使用join的方式,也会扫描200行数据,只不过要执行的sql语句会有101条,而使用join语句的情况下,却只有1条。相比使用join,不使用join,会增加100次与mysql的交互过程,整体的执行效率相比使用join反而更低。
由此可见,在被驱动表上可以使用到索引的情况下,join操作的效率还是比较高的。读到这里,你是否会改变对join的认识呢?还会想当然的认为join执行效率很低吗?
可能你会问,如果join的过程中,被驱动表上没有索引呢?的确,当被驱动表上没有索引的情况下,join的执行效率会变慢很多,显然,"join执行的效率低"这个认知,不是空穴来风,但是变慢的原因是什么呢?感兴趣的老铁可以看一下,这篇文章。
评论区